kubernetes监控
从整体把握监控
监控目的
及时发现已经出现的问题知道的越早才能解决的越快
提前预警可能发生的问题在问题还没有发生的时候
监控什么
系统基本指标 服务是跑在服务器上的,服务器的cpu、内存、磁盘、io、网络、load负载等等基础信息都必须要监控
服务基本信息 除了系统基本指标之外服务本身也要监控,服务占用多少内存、cpu、网络、磁盘、io、监听的端口在不在等等这些基本情况都要监控住
服务个性化信息 每种服务都有各自的特征也有各自自定义的参数,比如web服务常见的请求的排队情况、每秒请求次数、错误次数、请求处理时间等等
日志 还有一种比较常见的情况比如日志,不断的分析业务的日志,根据日志的异常数或者某些特定异常发生的频率来做预警
如何监控
数据采集 定时的采集数据,比如每分钟,每隔10秒采集一次数据;监控是一个比较长期持续的事情,采集一次或者几次的数据肯定是没有什么意义的
数据存储 一般会使用时间和次数来作为报警依据,比如说5分钟内某件事情发生了3次对外报警,3分钟内cpu使用持续超过70%报警,可以说大部分的报警场景都和时间有关系,所以说监控数据一般使用时间序列数据库来存储
定义报警规则 数据有了之后需要定义报警规则,上面提到的场景都是需要定义的
配置报警方式 报警的方式有很多,一般通过短信、邮件、钉钉、企业微信等等
业内常见的监控组件和方案
Zabbix 老牌的监控平台主要监控服务器的信息,有自己的采集存储
OpenFalcon 小米开源,支持自定义插件自定义模版
听云、监控宝 第三方公司的商业产品
业内提供了非常多的监控组件监控产品,根据业务的场景规模都有适合自己监控手段报警的阈值,甚至在一家公司发展的不同阶段报警的策略也会不停的发生变化,阈值更是需要不断的调整和优化,所以说监控在一个公司落地的时候肯定不是一撮而就的,而是一个不断去调整不断去迭代优化的过程
kubernetes的监控
每个节点的基础指标
每个容器的基础指标 一个进程对应一个容器,一个容器对应一个应用其实就是应用的监控
kubernetes集群组件 基础组件controllermanager、etcd、kube-proxy、kube-scheduler、apiserver的监控
要达到上面的监控目标,传统的监控组件并不太合适的。首先kubernetes集群变化坚持增加节点删除节点,容器更是会经常变化,如果静态部署监控服务显然是费力不讨好的事情,那应该使用什么方式去监控它呢?
Prometheus
曾几何时kubernetes监控有很多的方案,但随着时间的发展已经演变成以promethus为核心的一套统一的方案;kubernetes源自google的borg系统,同样prometheus也源自开发过borg系统工程师的想法发展而来,2016.5 prometheus正式加入CNCF 2018.8从CNCF毕业 说明项目具备一定的成熟和稳定性可以放心的投入生产
Prometheus是什么
一系列服务的组合 首先它并不是一个单独的服务而是
系统和服务的监控报警平台 包括但不限于kubernetes集群的监控,支持静态监控目标同时也支持动态服务发现
Prometheus特征
由metric名称和kv标识的多维数据模型 http_response_total{method="GET",entpoint="/api/get"}这里http_response_total就是metric名字,每个名字加上不同的kv组合都是一条单独的时间序列
灵活的查询语言(PromQL)
支持pull、push两种方式添加数据 虽然prometheus的设计是通过pull的方式主动获取数据,但是它也为push提供了支持
支持基于kubernetes服务发现的动态配置
架构
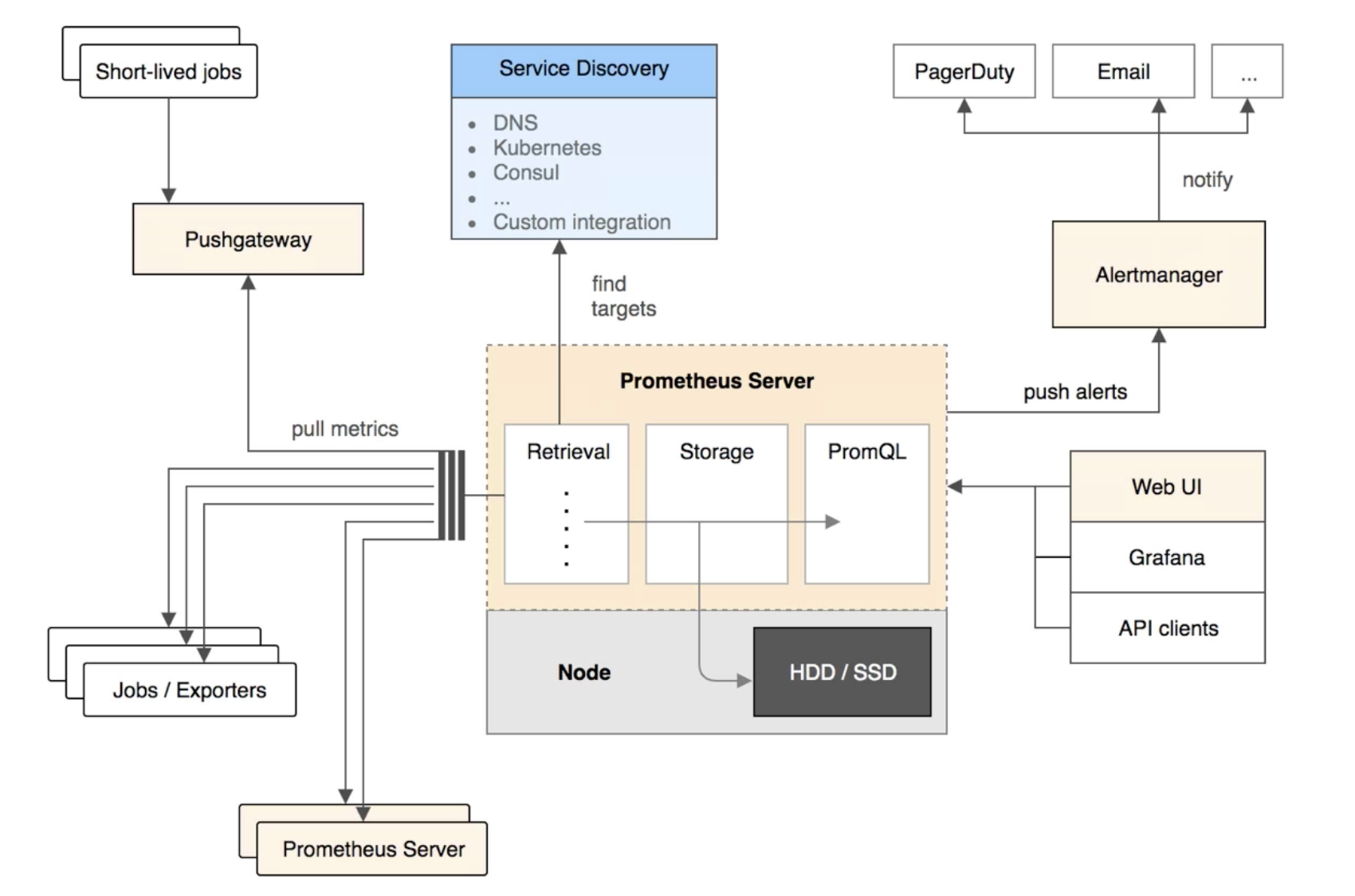
Prometheus由很多个组件组成,其中有很多组件也是可选的
Prometheus server是prometheus的核心组件,它通过pull的方式去拉取数据,这个过程就是Retrieval;数据拉取后通过Stroage存储,数据会保存在timescale db数据库中;数据存储后通过PromQL提供强大的查询支持
Jobs/Exporters是用来暴露指标让Retrieval来抓取的,通熟来说就干两个事一个是想方设法的采集到想要的数据,第二个是提供一个对外的http接口可以拿到采集的数据
Pushgateway支持push的方式将数据指标推送到网关,比如一些定时任务和一些一次性执行的任务,对server来说也是通过pull的方式从拉取数据回来
Service Discovery是prometheus支持的服务发现,支持DNS、Kubernetes、Consul、Custom integration,深入到系统内部去支持了它们的服务发现机制
Alertmanager当prometheus定义的规则被触发了之后就会把报警的信息push给Alertmanager,然后在Alertmanager里面支持自定义的报警规则,对报警做过滤聚合频率控制等等,最后实现报警的通知,通知也支持很多种方式可以发送到固定的http接口
Web UI prometheus可以支持多种的UI展现,最常见的Grafana,UI的实现主要的通过PromQL去对prometheus里面的数据做查询然后做丰富的展现
数据类型
prometheus的是key是metric名称和kv对的组成,它的value是一个long类型的整型值一般存储以下几种数据
Counter 用于记录累计的值,这个值会一直的增加不会减少,比如请求的次数,异常发生的次数
Gauge 常规数字可以变化,比如内存、cpu的变化
Histogram && Summary 主要用于统计和分析样本的分布情况,在大多数情况下会使用样本的平均值,比如cpu平均使用率,页面平均响应时间,但是这种方式有明显的问题,比如有一个nginx服务大多数的请求都维持在100ms以内,而有个别请求响应时间可能到了5s、10s 这种情况会导致平均值不能体现的长尾问题,最简单的处理方式是安装请求的时间范围分组,histogram和summary就是解决这种问题存在的,通过这两种指标可以快速的了解样本的分布情况
数据来源
服务器基础指标
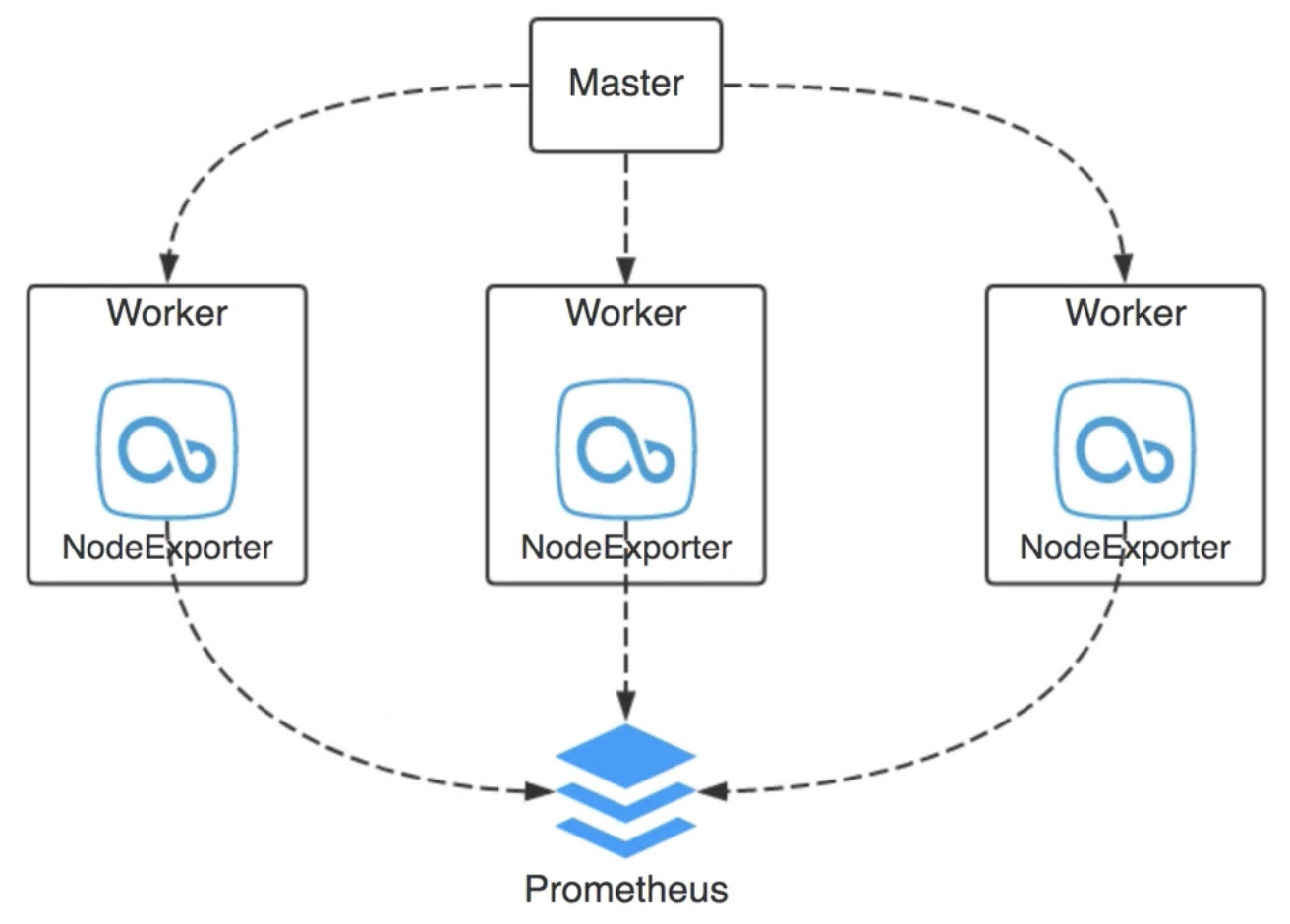
promethues提供了一个NodeExporter的工具,一般会以daemonset的方式运行在每台主机上,它的作用就是抓取服务器的基础信息比如负载、cpu、内存磁盘网络等等相关的一些机器指标的相关信息,它提供了一个http服务给prometheus pull数据
容器指标
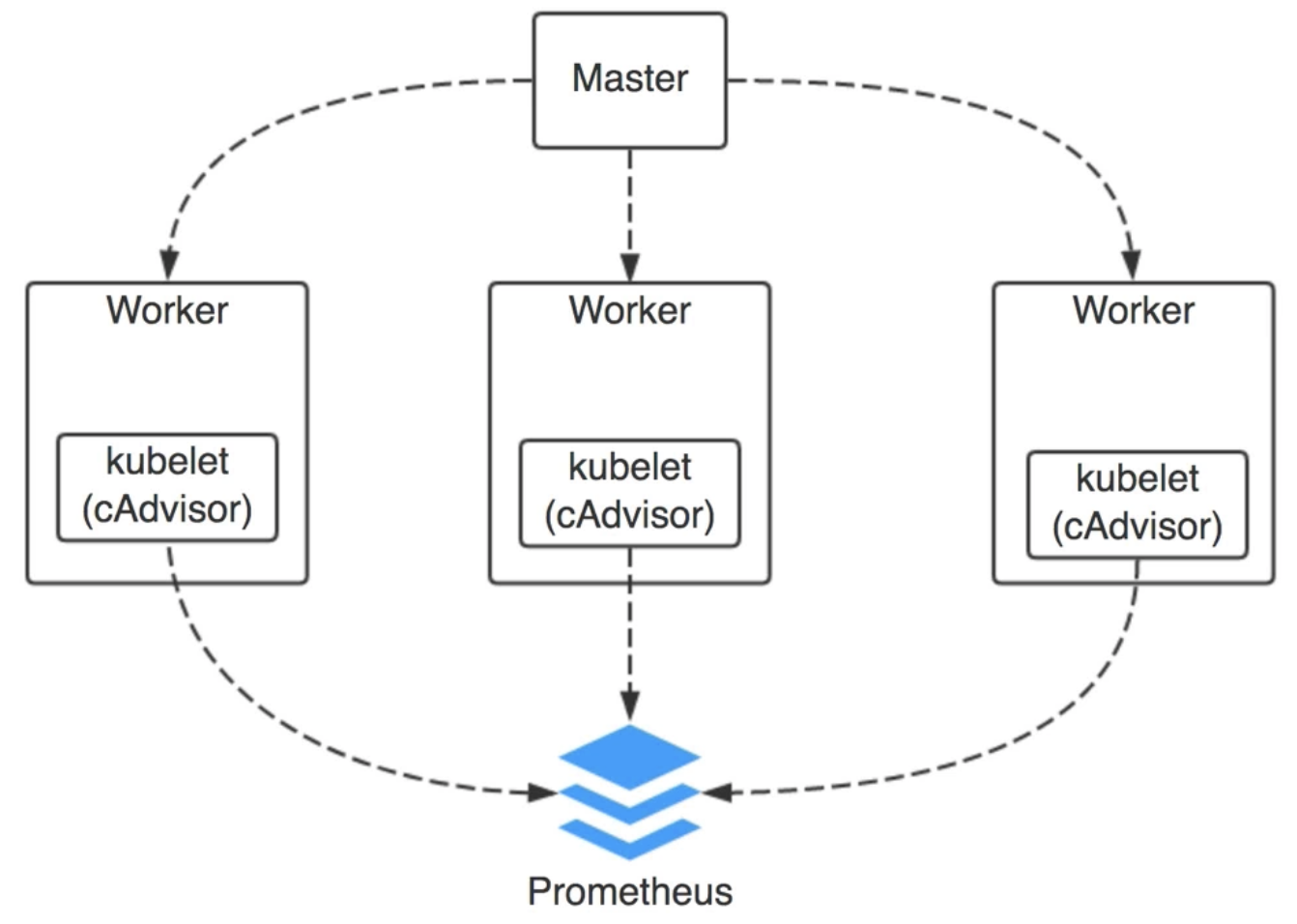
每个节点上上都会有一个kubelet服务,这个服务启动的时候会内置一个cAdvisor,cAdvirsor负责采集容器的基础信息,最后它也会启动一个http服务给prometheus pull数据
kubernetes组件
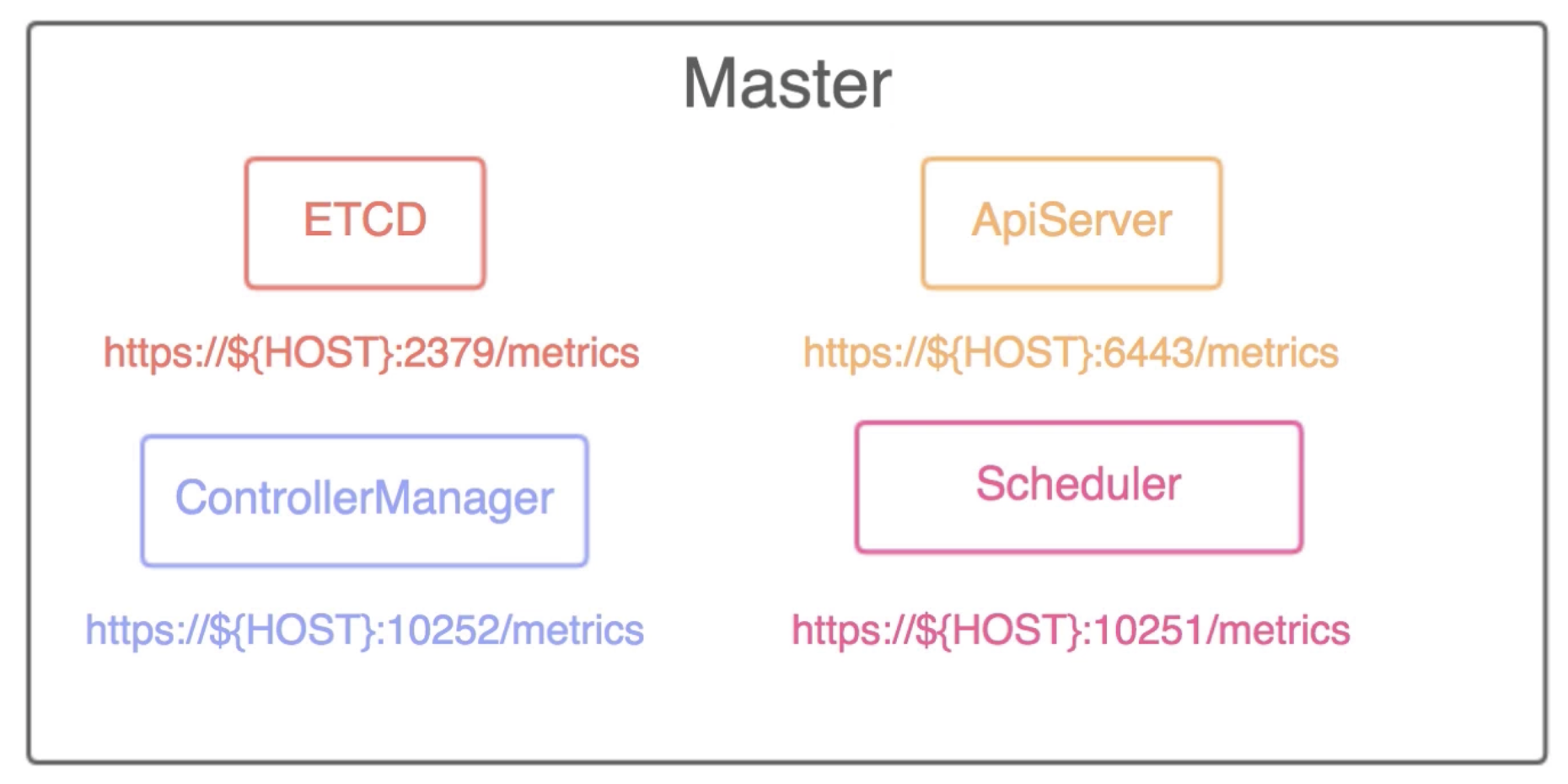
每个kubernetes相关的组件都自带metrics,只需要prometheus定期pull
Prometheus部署
部署方案选择
手动部署 最原始的就是手动部署直接把每个组件部署好运行,这种方式要求我们了解每个组件,如何进行部署,如何做高可用,如何让它们协同工作,如何做配置,复杂度非常高
Helm 相当于centos的yum是kubernets的包管理工具,用helm部署简单很多但部署后依然有一些配置工作
Prometheus Operator 利用了kubernetes的operator机制,本质上就是kubernetes的crd
Helm+Prometheus Operator 直接使用Prometheus Operator需要做的事情依然不少
Operator
自定义资源类型(CRD)+自定义控制器 pod、daemonset、deployment、server都是kubernetes预先定义好的资源,kubernetes也有自己的控制器去管理它们,控制器的本质就是代码循环不断的去看预期的状态与真实状态的差别并努力使它们保持一致,比如一个deployment定义的实例数是3现在只有1个实例控制器就会发现这样的差别然后再启动2个实例,在kubernetes1.7之后就支持CRD自定义资源类型
部署 kube-prometheus
从GitHub克隆kube-prometheus
git clone https://github.com/prometheus-operator/kube-prometheus.git
下载完成,进入项目的根目录
# Create the namespace and CRDs, and then wait for them to be availble before creating the remaining resources
kubectl create -f manifests/setup
# Wait until the "servicemonitors" CRD is created. The message "No resources found" means success in this context.
until kubectl get servicemonitors --all-namespaces ; do date; sleep 1; echo ""; done
kubectl create -f manifests/
我们首先创建namespace和CustomResourceDefinitions,以避免在部署监控组件时出现竞争情况。或者,可以用一个命令应用两个文件夹中的资源kubectl create -f manifests/setup -f manifests,但是可能需要多次运行该命令才能成功创建所有组件。
查看CRD类型:
[root@a1 ~]# kubectl get crd |grep coreos
alertmanagerconfigs.monitoring.coreos.com 2022-08-11T01:37:54Z
alertmanagers.monitoring.coreos.com 2022-08-11T01:37:54Z
podmonitors.monitoring.coreos.com 2022-08-11T01:37:54Z
probes.monitoring.coreos.com 2022-08-11T01:37:54Z
prometheuses.monitoring.coreos.com 2022-08-11T01:37:54Z
prometheusrules.monitoring.coreos.com 2022-08-11T01:37:54Z
servicemonitors.monitoring.coreos.com 2022-08-11T01:37:54Z
thanosrulers.monitoring.coreos.com 2022-08-11T01:37:54Z
查看特定CRD类型下的实例:
[root@a1 ~]# kubectl get prometheuses -n monitoring
NAME VERSION REPLICAS AGE
k8s 2.32.1 2 97d
[root@a1 ~]# kubectl get servicemonitors -n monitoring
NAME AGE
alertmanager-main 97d
blackbox-exporter 97d
coredns 97d
example-app 92d
grafana 97d
kube-apiserver 97d
kube-controller-manager 97d
kube-scheduler 97d
kube-state-metrics 97d
kubelet 97d
node-exporter 97d
prometheus-adapter 97d
prometheus-k8s 97d
prometheus-operator 97d
查看创建的 Service:
kubectl get svc -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager-main ClusterIP 10.110.204.224 <none> 9093/TCP 23h
alertmanager-operated ClusterIP None <none> 9093/TCP,6783/TCP 23h
grafana ClusterIP 10.98.191.31 <none> 3000/TCP 23h
kube-state-metrics ClusterIP None <none> 8443/TCP,9443/TCP 23h
node-exporter ClusterIP None <none> 9100/TCP 23h
prometheus-adapter ClusterIP 10.107.201.172 <none> 443/TCP 23h
prometheus-k8s ClusterIP 10.107.105.53 <none> 9090/TCP 23h
prometheus-operated ClusterIP None <none> 9090/TCP 23h
prometheus-operator ClusterIP None <none> 8080/TCP 23h
可以看到上面针对 grafana 和 prometheus 都创建了一个类型为 ClusterIP 的 Service,当然如果我们想要在外网访问这两个服务的话可以通过创建对应的 Ingress 对象或者使用 NodePort 类型的 Service。